认识Hive
首先我们要知道hive到底是做什么的。下面这几段文字很好的描述了hive的特性:
1、hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供完整的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。
架构
下面我来讲讲hive的技术架构,大家先看下面的架构图: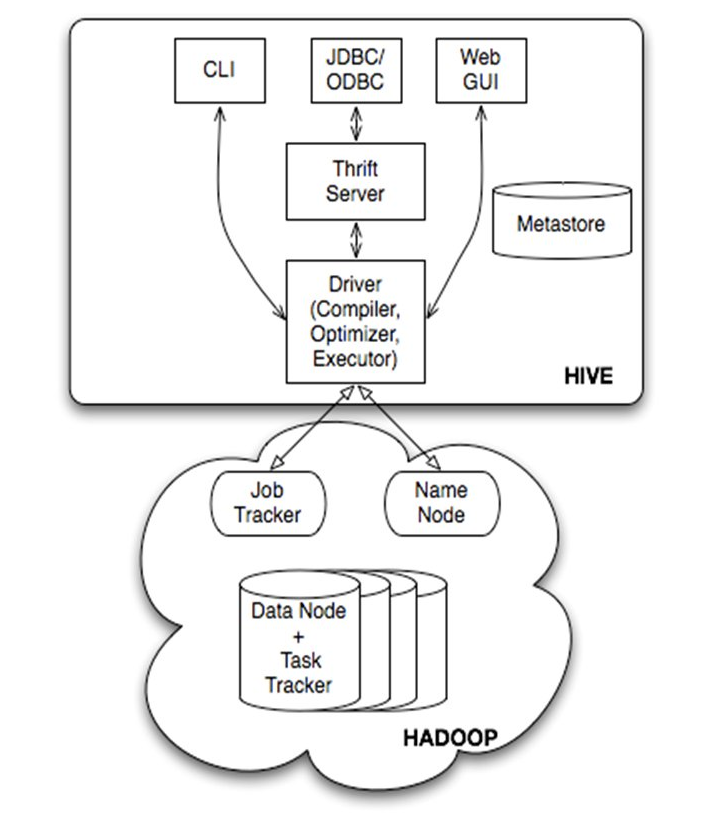
Hive架构包括如下组件:CLI(command line interface)、JDBC/ODBC、Thrift Server、WEB GUI、metastore和Driver(Complier、Optimizer和Executor),这些组件我可以分为两大类:服务端组件和客户端组件。
首先讲讲服务端组件:Driver组件:该组件包括Complier、Optimizer和Executor,它的作用是将我们写的HiveQL(类SQL)语句进行解析、编译优化,生成执行计划,然后调用底层的mapreduce计算框架。
Metastore组件:元数据服务组件,Hive 将元数据存储在数据库中,如 mysql、derby。Hive 中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。元数据对于hive十分重要,因此hive支持把metastore服务独立出来,安装到远程的服务器集群里,从而解耦hive服务和metastore服务,保证hive运行的健壮性
Thrift服务:thrift是facebook开发的一个软件框架,它用来进行可扩展且跨语言的服务的开发,hive集成了该服务,能让不同的编程语言调用hive的接口。
客户端组件:CLI:command line interface,命令行接口。
Thrift客户端:上面的架构图里没有写上Thrift客户端,但是hive架构的许多客户端接口是建立在thrift客户端之上,包括JDBC和ODBC接口。
WEBGUI:hive客户端提供了一种通过网页的方式访问hive所提供的服务。这个接口对应hive的hwi组件(hive web interface),使用前要启动hwi服务。
Hive的执行流程如下图所示: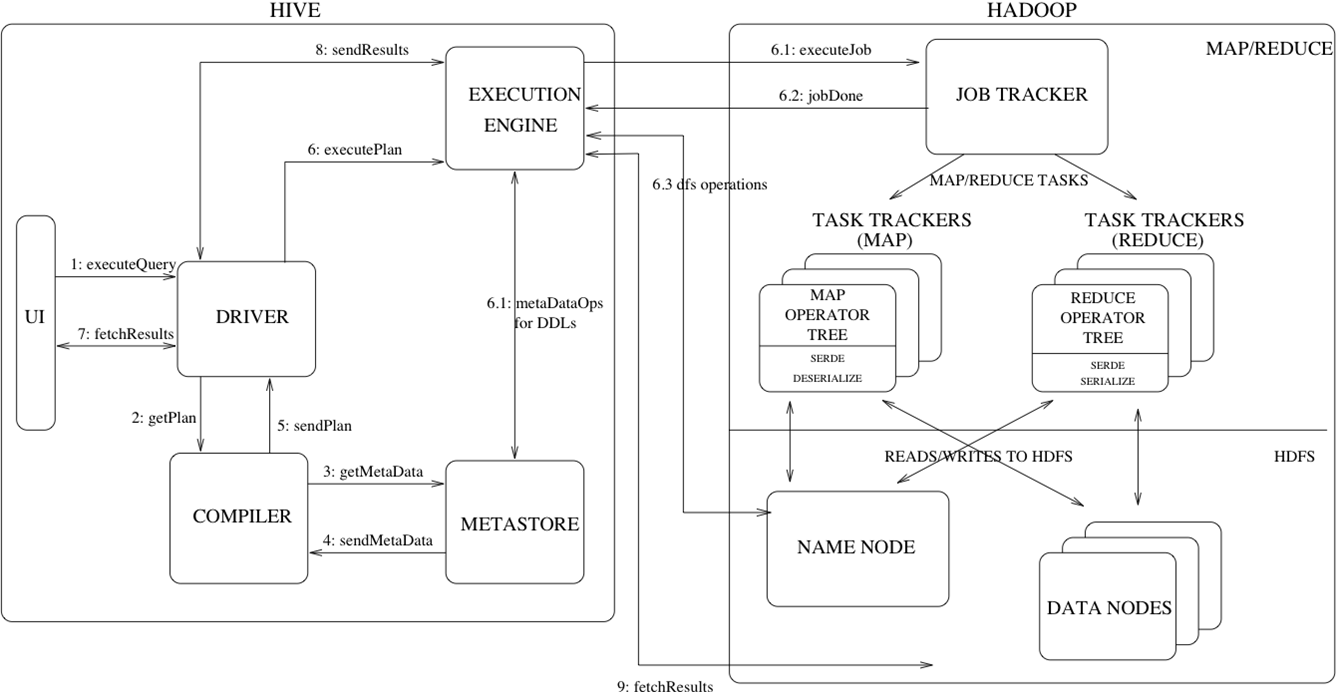
Hive基本操作
创建表:
1 | hive> CREATE TABLE pokes (foo INT, bar STRING); |
创建一个新表,结构与其他一样
1 | hive> create table new_table like records; |
创建分区表:
1 | hive> create table logs(ts bigint,line string) partitioned by (dt String,country String); |
加载分区表数据:
1 | hive> load data local inpath '/home/hadoop/input/hive/partitions/file1' into table logs partition (dt='2001-01-01',country='GB'); |
展示表中有多少分区:
1 | hive> show partitions logs; |
展示所有表:
1 | hive> SHOW TABLES; |
显示表的结构信息
1 | hive> DESCRIBE invites; |
更新表的名称:
1 | hive> ALTER TABLE source RENAME TO target; |
添加新一列
1 | hive> ALTER TABLE invites ADD COLUMNS (new_col2 INT COMMENT 'a comment'); |
删除表:
1 | hive> DROP TABLE records; |
删除表中数据,但要保持表的结构定义
1 | hive> dfs -rmr /user/hive/warehouse/records; |
从本地文件加载数据:
1 | hive> LOAD DATA LOCAL INPATH '/home/hadoop/input/ncdc/micro-tab/sample.txt' OVERWRITE INTO TABLE records; |
显示所有函数:
1 | hive> show functions; |
查看函数用法:
1 | hive> describe function substr; |
查看数组、map、结构
1 | hive> select col1[0],col2['b'],col3.c from complex; |
内连接:
1 | hive> SELECT sales.*, things.* FROM sales JOIN things ON (sales.id = things.id); |
查看hive为某个查询使用多少个MapReduce作业
1 | hive> Explain SELECT sales.*, things.* FROM sales JOIN things ON (sales.id = things.id); |
外连接:
1 | hive> SELECT sales.*, things.* FROM sales LEFT OUTER JOIN things ON (sales.id = things.id); |
in查询:Hive不支持,但可以使用LEFT SEMI JOIN
1 | hive> SELECT * FROM things LEFT SEMI JOIN sales ON (sales.id = things.id); |
Map连接:Hive可以把较小的表放入每个Mapper的内存来执行连接操作
1 | hive> SELECT /*+ MAPJOIN(things) */ sales.*, things.* FROM sales JOIN things ON (sales.id = things.id); |
创建视图:
1 | hive> CREATE VIEW valid_records AS SELECT * FROM records2 WHERE temperature !=9999; |
查看视图详细信息:
1 | Hive> DESCRIBE EXTENDED valid_records; |
与关系数据库的区别
使用hive的命令行接口,感觉很像操作关系数据库,但是hive和关系数据库还是有很大的不同,下面我就比较下hive与关系数据库的区别,具体如下:
1、hive和关系数据库存储文件的系统不同,hive使用的是hadoop的HDFS(hadoop的分布式文件系统),关系数据库则是服务器本地的文件系统;
2、hive使用的计算模型是mapreduce,而关系数据库则是自己设计的计算模型;
3、关系数据库都是为实时查询的业务进行设计的,而hive则是为海量数据做数据挖掘设计的,实时性很差;实时性的区别导致hive的应用场景和关系数据库有很大的不同;
想象你在操作RMDB数据库,如果是全表扫描,就用Hive+Hadoop,如果是索引访问,就用HBase+Hadoop 。
4、Hive本身不存储和计算数据,它完全依赖于HDFS和MapReduce,Hive中的表纯逻辑。
hbase是物理表,不是逻辑表,提供一个超大的内存hash表,搜索引擎通过它来存储索引,方便查询操作。
5、Hive很容易扩展自己的存储能力和计算能力,这个是继承hadoop的,而关系数据库在这个方面要比数据库差很多。
6、关系数据库里,表的加载模式(数据库存储数据的文件格式)是在数据加载时候强制确定的,如果加载数据时候发现加载的数据不符合模式,关系数据库则会拒绝加载数据,这个就叫“写时模式”,写时模式会在数据加载时候对数据模式进行检查校验的操作。
Hive在加载数据时候和关系数据库不同,hive在加载数据时候不会对数据进行检查,也不会更改被加载的数据文件,而检查数据格式的操作是在查询操作时候执行,这种模式叫“读时模式”。在实际应用中,写时模式在加载(写)数据时候会对列进行索引,对数据进行压缩,因此加载数据的速度很慢,但是当数据加载好了,我们去查询数据的时候,速度很快。但是当我们的数据是非结构化,存储模式也是未知时候,关系数据操作这种场景就麻烦多了,这时候hive就会发挥它的优势。
7、关系数据库一个重要的特点是可以对某一行或某些行的数据进行更新、删除操作,hive不支持对某个具体行的操作,hive对数据的操作只支持覆盖原数据和追加数据。Hive也不支持事务和索引。更新、事务和索引都是关系数据库的特征,这些hive都不支持,也不打算支持,原因是hive的设计是海量数据进行处理,全数据的扫描是常态,针对某些具体数据进行操作的效率是很差的,对于更新操作,hive是通过查询将原表的数据进行转化最后存储在新表里,这和传统数据库的更新操作有很大不同。
8、Hive也可以在hadoop做实时查询上做一份自己的贡献,那就是和hbase集成,hbase可以进行快速查询,但是hbase不支持类SQL的语句,那么此时hive可以给hbase提供sql语法解析的外壳,可以用类sql语句操作hbase数据库。
Hive数据类型
Hive支持两种数据类型,一类叫原子数据类型,一类叫复杂数据类型。
原子数据类型包括数值型、布尔型和字符串类型(和JAVA基本数据类型一一对应)hive不支持日期类型,在hive里日期都是用字符串来表示的,而常用的日期格式转化操作则是通过自定义函数进行操作。
复杂数据类型包括数组(ARRAY)、映射(MAP)和结构体(STRUCT)
下面我们看看hive使用复杂数据类型的实例,建表:
1 | Create table complex(col1 ARRAY<INT>, |
Hive数据模型
hive的数据模型包括:database、table、partition和bucket。
表
Hive中的表和关系型数据库中的表在概念上很类似,每个表在HDFS中都有相应的目录用来存储表的数据,这个目录可以通过${HIVE_HOME}/conf/hive-site.xml配置文件中的 hive.metastore.warehouse.dir属性来配置,这个属性默认的值是/user/hive/warehouse(这个目录在 HDFS上),我们可以根据实际的情况来修改这个配置。
如果我有一个表wyp,那么在HDFS中会创建/user/hive/warehouse/wyp 目录(这里假定hive.metastore.warehouse.dir配置为/user/hive/warehouse);wyp表所有的数据都存放在这个目录中。
外部表
Hive中的外部表和表很类似,但是其数据不是放在自己表所属的目录中,而是存放到别处,这样的好处是如果你要删除这个外部表,该外部表所指向的数据是不会被删除的,它只会删除外部表对应的元数据;而如果你要删除表,该表对应的所有数据包括元数据都会被删除。
下面是创建表的实例语句:
1 | Create table tuoguan_tbl (flied string); |
外部表创建的实例:
1 | Create external table external_tbl (flied string) |
hive加载数据时候不会对元数据进行任何检查,只是简单的移动文件的位置,如果源文件格式不正确,也只有在做查询操作时候才能发现,那个时候错误格式的字段会以NULL来显示。
分区(partition)
hive里分区的概念是根据“分区列”的值对表的数据进行粗略划分的机制,在hive存储上就体现在表的主目录(hive的表实际显示就是一个文件夹)下的一个子目录,这个文件夹的名字就是我们定义的分区列的名字,分区列不是表里的某个字段,而是独立的列,我们根据这个列存储表的里的数据文件。使用分区是为了加快数据分区的查询速度而设计的,我们在查询某个具体分区列里的数据时候没必要进行全表扫描。
创建分区:
1 | Create table logs(ts bigint,line string) |
加载数据:Load data local inpath ‘/home/hadoop/par/file01.txt’ into table logs partition (dt=’2012-06-02’,country=’cn’);
在hive数据仓库里实际存储的路径如下所示:
1 | /user/hive/warehouse/logs/dt=2013-06-02/country=cn/file1.txt |
我们看到在表logs的目录下有了两层子目录dt=2013-06-02和country=cn
查询操作:Select ts,dt,line from logs where country=’cn’
这个时候我们的查询操作只会扫描file1.txt和file2.txt文件。
桶(bucket)
上面的table和partition都是目录级别的拆分数据,bucket则是对数据源数据文件本身来拆分数据。使用桶的表会将源数据文件按一定规律拆分成多个文件,要使用bucket,我们首先要打开hive对桶的控制,命令如下:set hive.enforce.bucketing = true
1 | 示例: |
桶文件是按指定字段(cluster字段)值进行hash,然后取余桶的个数例如上面例子2
桶运用的场景有限,一个是做map连接的运算,我在后面的文章里会讲到,一个就是取样操作了
1 | 查看sampling数据: |
tablesample是抽样语句,语法:TABLESAMPLE(BUCKET x OUT OF y)
y必须是table总bucket数的倍数或者因子。hive根据y的大小,决定抽样的比例。例如,table总共分了64份,当y=32时,抽取 (64/32=)2个bucket的数据,当y=128时,抽取(64/128=)1/2个bucket的数据。x表示从哪个bucket开始抽取。例如,table总bucket数为32,tablesample(bucket 3 out of 16),表示总共抽取(32/16=)2个bucket的数据,分别为第3个bucket和第(3+16=)19个bucket的数据。
Hive的数据存储
首先,Hive 没有专门的数据存储格式,也没有为数据建立索引,用户可以非常自由的组织 Hive 中的表,只需要在创建表的时候告诉 Hive 数据中的列分隔符和行分隔符,Hive 就可以解析数据。
其次,Hive 中所有的数据都存储在 HDFS 中,Hive 中包含以下数据模型:Table,External Table,Partition,Bucket。
1、Hive 中的 Table 和数据库中的 Table 在概念上是类似的,每一个 Table 在 Hive 中都有一个相应的目录存储数据。例如,一个表 pvs,它在 HDFS 中的路径为:/wh/pvs,其中,wh 是在 hive-site.xml 中由 ${hive.metastore.warehouse.dir} 指定的数据仓库的目录,所有的 Table 数据(不包括 External Table)都保存在这个目录中。
日志
Hive中的日志分为两种
1、系统日志,记录了hive的运行情况,错误状况。
2、Job 日志,记录了Hive中job的执行的历史过程。
系统日志存储在什么地方呢 ?
在hive/conf/ hive-log4j.properties 文件中记录了Hive日志的存储情况
默认的存储情况:
hive.root.logger=WARN,DRFA
hive.log.dir=/tmp/${user.name} # 默认的存储位置
hive.log.file=hive.log # 默认的文件名
Job日志又存储在什么地方呢 ?
//Location of Hive run time structured log file
HIVEHISTORYFILELOC(“hive.querylog.location”, “/tmp/“ + System.getProperty(“user.name”)),
默认存储与 /tmp/{user.name}目录下。